Web scraping is as old as the web itself, it is a very widely known term in the programming world, and in online businesses in general. Scraping allows you to gather multiple sources of data in one compact place, from within which you can make your own data queries, and display information however you like.
In my personal experience, I’ve seen web scrapers being used to build automated product websites, article directories, and full-scale projects that involve a lot of interaction with data. What do all of these have in common? Money. The average person looking for a web scraper will be thinking in terms of money.
Are you a PHP coder? Take a look at these PHP libraries that are for working with the HTTP protocol and also for scraping content.
What other uses are there for web scrapers, which are the most common ones? Funny to think about this, the first thing that came to my mind when thinking of other uses for scraping was a tweet that was sent out earlier this year by Matt Cutts, one of the people behind Google’s spam team.
“If you see a scraper URL outranking the original source of content in Google, please tell us about it.” – Matt told his Twitter fans. Just a few moments later, Dan Barker – an online entrepreneur; made a quite amusing reply to show what the real problem with Google is:

I thought it was pretty hilarious, as did 30,000 other people who took the time to retweet that statement. The lesson here is that web scraping is all around us. Try to imagine a world where a price comparison website would need to have a separate set of employees, just to have them check the prices again, and again, for each new request. A nightmare!
Web scraping has many sides to it, there are certainly many uses for it as well, here are a few examples (feel free to skip this to get right into our list of web scraping tools) that I think define what scraping is about, and probably shows that it’s not always about stealing data from others.
• Price Comparison — As I said, one of the great uses for scraping is the ability to compare prices and data in a more efficient manner. Instead of having to do all the checks manually, you can have a scraper in place; doing all the requests for you.
• Contact Details — You could consider this type of scraping as something on a thin line, but it is possible to scrape for people’s details; names, emails, phone numbers, etc,. by using a web scraper.
• Social Analysis — I think this one is getting less attention than it deserves, with modern technology – we can really immerse ourselves in the life of others, and by scraping social websites like Twitter or Facebook, we can come to conclusions of what different groups of people like. (It goes a lot deeper than that!)
• Research Data — Quite similar to what I said above, large amounts of data can be scraped in one place and then used as a general database for building amazing, and informational websites or products.
These all were, on the top of my head, having a quick look online led me to this blog post, you’ll find a few more suggestions on the uses of web scraping there.
Some people will scrape the contents of a website and post it as their own, in effect stealing this content. This is a big no-no for the same reasons that taking someone else’s book and putting your name on it is a bad idea. Intellectual property, copyright and trademark laws still apply on the internet and your legal recourse is much the same. — Justin Abrahms, QuickLeft
It is not that hard of a thing to do, to imagine a fellow webmaster being frustrated over a company that has stolen all of his data, and is now making a huge profit out of it. The worst part? In many cases, it is near next-to-impossible to prove that these people are doing what you know they are, scraping, and using your data.
I think that covers my initial introduction to web scraping, and my last piece of advice is this – learn Python; it is one of the most common programming languages used for scraping, extracting, and organizing data. Luckily, it is also incredibly easy to learn, and with the use of different frameworks – getting up and running will be a breeze.
1. Import.IO
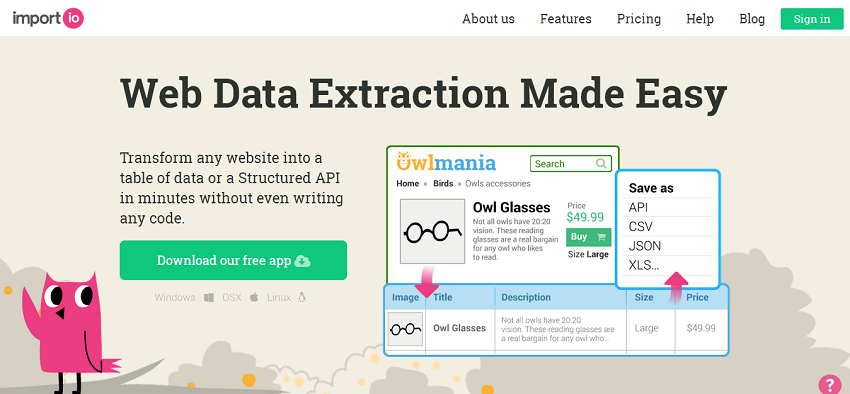
I love what these guys are doing at Import.IO, even though it is a little on the expensive side. Enterprises who are looking for more flexibility and algorithmic access can get in touch with the sales team, while everyone else enjoys the product free for life.
Their web scraping tool is available for all major operating systems (Mac, Linux, Windows), and comes equipped with an amazing set of features. I’m particularly fond of Authenticated APIs, Datasets, and Cloud Storage. But, the crown jewel is their own blog – a place where you can find user feedback, and a great number of tutorials and how-to guides.
In my experience, I found that scraping a website like ThemeForest turned out to be incredibly easy, but I quickly grew tired of the idea and so didn’t really continue to explore the possibilities. I’d love to hear your own stories about Import, and whether you think it is one of the best free tools for scraping-out there.
2. Zenscrape
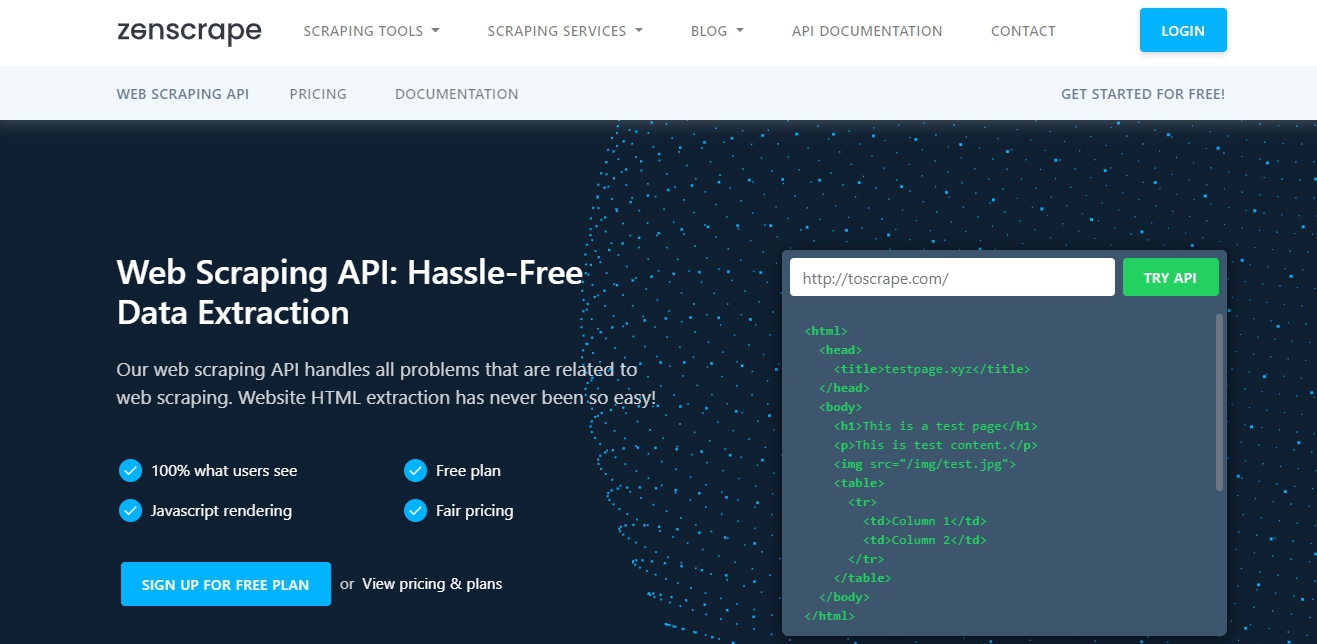
Zenscrape is one of the recent Web Scraping API tools that is gaining popularity for hassle-free data extraction. It’s actually a quite interesting tool that handles all problems that are related to web scraping along with HTML extraction. It is a fast, easy-to-use API, & offers great performance regardless of your requests.
Zenscrape allows you to:
- Crawl any website
- Monitor prices and product information
- Build a fully automated pricing and investment strategy
- Getting sales lead
- Scrape review platforms
- Scrape vacancies from job boards or career pages & much more!
It comes with both free & paid plans. Actually, you can choose from a wide variety of plans depending upon your needs. Click to learn more about Zenscrape.
3. Scrapy
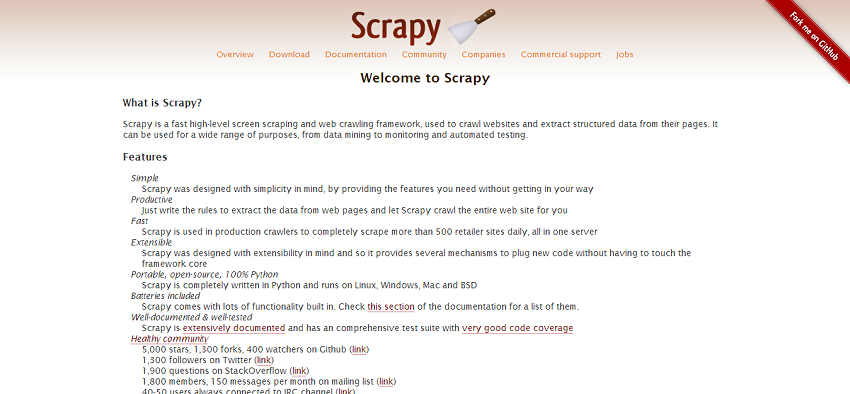
Scrapy is a fast high-level screen scraping and web crawling framework, used to crawl websites and extract structured data from their pages. It can be used for a wide range of purposes, from data mining to monitoring and automated testing.
Like I said, Python is quite famous for being easy to learn and easy to use when it comes to scraping the web. Scrapy gives you all the necessary tools, documentation, and examples to help you get started within minutes. You’ll need Python installed, and some basic understanding of the command line.
4. Apache Nutch™
The lack of a GUI (graphics interface) makes this tool-less appealing to the beginner class, but it is a widely used web crawling tool (very possibly, the most widely used) that can help to achieve large proportions of websites in a matter of seconds. Apache Nutch™ is flexible, powerful, and is built alongside the popular Apache Solr search server.
Nutch is open-source, and offers both modular and pluggable interfaces for concluding crawling matters. You could easily build your own search engine if you wanted to. I’m fond of this installation guide, which is extended into further detail if you’re interested in giving it a shot.
5. Scrapinghub

Scrapinghub is a very advanced platform when it comes to crawling the web using ‘spiders’. Their platform enables you to launch multiple crawlers at a time, without the requirement of deep monitoring of what is going on in the background. You simply give it the necessary data that it needs, and it will do the rest by itself. Everything is stored in the Scrapinghub – highly available – database and retrievable from our API.
I really like their latest open-source product, it is called Portia and it will enable you to do some custom scraping on your own, mostly to get a feel of how a visual web scraper works, and what kind of data it is possible to scrape and archive.
6. UBot Studio
 UBot Studio 5 Build Web Automation and Marketing Software” width=”800″ height=”393″ />
UBot Studio 5 Build Web Automation and Marketing Software” width=”800″ height=”393″ />
Anything you do online can be automated with UBot Studio. It will help you collect and analyze information, synchronize online accounts, upload and download data, and finish any other job that you might do in a web browser, and beyond.
UBot Studio was recommended for this list by one of the people who have left a comment on this post. I didn’t think much of it at first, but after having taken a second look, UBot Studio looks like a fairly promising platform that can change the way you or your business, interacts with the daily tasks of the web technology.
The number of things that UBot Studio can help you do is growing with every release: –
• You can create a network of blogs and manage them automatically with UBot.
• Easily create user accounts on the most popular social networks with a single click.
• Update your blogs and social networks automatically from one single window.
• Mass upload videos to the most favorite video sites on the web.
• Conduct research tasks that can yield insight about keywords and their according niches.
• Works with popular platforms such as WordPress, Blogger, and even cPanel for all your hosting needs.
• …. and so many more features that you can find here.
It definitely is a little bit different from other scraping tools that we have on this particular list, but with such a wide array of features, I think this particular platform deserves to be noticed. Unfortunately, it won’t be free to use it, but if you’ve been looking for a similar solution for your projects, perhaps this is the one to go for. We don’t use affiliate links, so it’s up to you to decide whether UBot Studio can help your business.
Apps & Tools for Crawling the Web
You’ve got a lot of choices right now, find the right tool that works for you, and keep playing with it. I think that there is a lot of good that we can do, by using these tools for the right reasons. Honestly, I just don’t see the point in scraping Wikipedia’s full archive of pages and then submitting them on your own blog.
Find something meaningful, something that would impress others and try and work it out. The least of our worries should be the ability to do it, as there are more than enough tutorials and guides out there; on how to use these tools for the maximum potential.
I hope that you’ll find something worth your time, but I also encourage you to share your own tools that you use for web scraping, and I’d love to try them out myself.
Check out cheerio for node… I built a craigslist scraper in an afternoon
Thanks for the great summary, I hadn’t heard of ScrapingHub before. Scrapy is my tool of choice if I need to quickly collect data from a single domain or website. If you are interested in some of the larger scale open source crawlers, I recently wrote up a comparison on open source web crawlers
Good article. I wrote a “guide” to scraping earlier this year. It’s a little more technical than the above as it’s aimed directly at programmers, and is slightly more tailored towards Python, but could still be of use to some people: http://jakeaustwick.me/python-web-scraping-resource/
Keep your eyes peeled for some new features in import.io in the next week. #insidertip
Thanks for sharing this list. I’ll be reviewing some of them. At the moment, we use Feedity – https://feedity.com to create custom feeds. It works very well for most sites.
Hi Alex, nice article. I also did a similar write up comparing import.io, embed.ly and diffbot and my own extraction algorithm (written in Python):
http://rodricios.github.io/posts/solving_the_data_extraction_problem.html
As the article will show, my package does well against those closed-source solutions that I mention above. Just to expand on what my library does, it uses a super simple unsupervised learning approach to classify data vs. non-data from a given website.
You can find the library here:
https://github.com/datalib/libextract
Cheers,
Rodrigo
P.S. Please feel free to drop a plug on my site as your article is both relevant to data extraction AND your remarks on different data-extraction services are inline with my own :)
Honestly, I can’t imagine a list of scrapers that doesn’t include Ubot Studio in the top 3. Anyone who has ever tried to automate anything – without knowing code – has used this program like a savior. I actually know code and I still use it because of the community of experts that use it advise in ways I didn’t think were possible. The community is insanely talented and always coming out with new plugins and tips, tutorials and tricks… it is – hands down – the best web automation and scraping tool – ever. I don’t have any monetary gain by saying this and I am not affiliated with the company. Find me in the community under “pacbotter”.
Visual Web Scraper is a very powerful tool as well. I’ve also used Ubot Studio extensively in the past. Although now that I only use Linux, this has confined my Ubot usage to history. Strangely, Ubot fails to mention on their site that it is for Windows only.
To date, I’m still searching for a good Linux equivalent.
Thank u for this amazing tools…I needed a one urgently…hoping one of this will do my job
Hi Alex,
Excellent article. Do you know if any of this can make email scrap?
Thanks!
I have tried all the software above. I think each software has their own Pros and Cons. But no one really satisfies me very well. But I find another one free web scraping tool, Octoparse. It’s simple to operate and has rich video tutorials. It’s much more suitable for ones without any coding knowledge.
Hi Alex.
I’m using the scraping tool called http://www.octoparse.com/?sb for research data analysis.
Tools you mentioned in the article, which one can be the best alternative for this one I’m using.
Great article about web scrapers. I believe another one to include is Mozenda. Mozenda can extract data from any website and format it into structured data that can be easily published and distributed.
I think that https://dexi.io/ is missing from your list – but otherwise a great list. Thanks :-)
I have been exploring for a little for any hjgh quality articles or weblog posts in this sort off space . Exploring in Yahoo I eventually stumbled upon thks web site. Studying this info So i amm glad to show that I have ann increedibly just rigbht uncanny feeling I fouund out just what I needed. I most certainly wilpl make sure to do nott overlook this site and provides it a look on a constant basis.
I heard that you need proxies for web crawling is that true? Something to do with IP blocking. Other people who crawl suggested using Oxylabs.io proxies, but want to make sure it is actually necessary as their service is on the pricier side and my crawling will not be a big operation.
Thanks for sharing! I think ScrapeStorm is also a good web scraping tool, you can have a try.
This is an amazing list! You can also checkout fastractor, its really an easy and authentic took for data extracting and scrapping.