
Who codes in PHP? It seems that majority of web developers do, there is a funny joke going around the web right now…people are eager to find every reason in the book to not like PHP, but when it comes to finding the perfect language for a simple freelance project – it’s always PHP that people go for.
In this post we’re taking a look at some libraries that we can use to learn more about using the HTTP within our PHP code, how we can avoid using the built-in API wrappers, and instead use something much easier and more manageable, but also some stuff that can help us to scrape websites and store data in a way that’s most necessary for our current needs.
Here’s the list of PHP Libraries
1. Guzzle
The development of websites usually comes down to two things: the front-end, and the back-end. The new websites that we’re seeing enter the world wide web right now are mostly based on front-end technology, while the old static/dynamic websites are still dependent on the back-end database. In order to talk to each other, there is usually the need to use an API.
Guzzle is an independent HTTP client for PHP, which means that you don’t have to depend on stuff like cURL, SOAP, or REST to make your pulls. It can prove to be a big time saver, and can definitely come in handy for specific projects.
2. Requests
At the moment, HTTP is still the very thing that makes the whole web world go around, so it makes sense when there are lots of interesting libraries available for dealing with HTTP, in this case – with HTTP requests. The idea is that Requests can provide a better API wrapper than cURL. It seems that many developers are agreeing to that fact.
3. HTTPFul
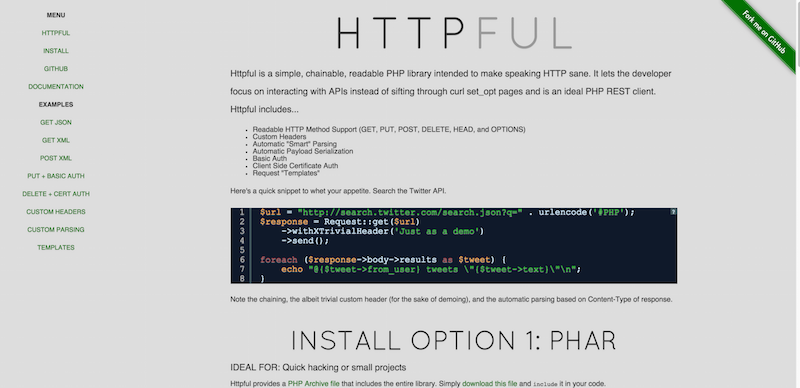
Httpful is a simple, chainable, readable PHP library intended to make speaking HTTP sane. It lets the developer focus on interacting with APIs instead of sifting through curl set_opt pages and is an ideal PHP REST client.
Here are the features of Httpful:
• Readable HTTP Method Support (GET, PUT, POST, DELETE, HEAD, and OPTIONS)
• Custom Headers
• Automatic “Smart” Parsing
• Automatic Payload Serialization
• Basic Auth
• Client Side Certificate Auth
• Request “Templates”
It’s a fairly quickly evolving project. There are Phar, Composer and Source files available for those who might desire them, and you can also become a part of the project by participating in finding bugs or sharing new ideas.
4. PHP VCR

Record your test suite’s HTTP interactions and replay them during future test runs for fast, deterministic, accurate tests. The features include things like:
• Can record HTTP(s) interactions automatically and replay them back to you with very little code work.
• Supports YAML and JSON for storing the data, but can be configured to your own custom serializer.
• All the common HTTP extensions and functions are supported.
• and many, many more..>
You might not need this testing tool right now, but keep it mind for possible future projects that you’re going to be working on, handy library that’s easy to setup and use.
5. Buzz
There isn’t much to say about Buzz, other than it is a lightweight HTTP client that you can use to store and retrieve data, very good for beginners to learn more about HTTP clients and how they work in the real world.
6. Goutte
A few years ago, web scraping was something that only the cool kids got to do, and while we have covered some scraping tools individually here on CodeCondo already, it seems that we’ve yet to see the true potential of web scraping. Although, I’m constantly seeing and becoming aware of more services, scripts and ways of putting together automated websites that require hardly any work, and are being treated as unique websites.
The Goutte library is going to give you a nice kickstart on how to scrape content using your PHP skills, you can use the Goutte API to scrape/screen websites and then code stuff to extract data as per your own requirements.
Conclusion: –
We hope that you’ve enjoyed this roundup, and if you would like to share some of your own favorite libraries on this particular technology, please do so in the comment section.
nice for this info this is very help ful knowledge for me